

Two of the biggest catchphrases being thrown around today in computing are Artificial Intelligence (AI) and Machine Learning. Many times people use them interchangeably. The truth is that AI encompasses a lot more than just Machine Learning, but Machine Learning is one of the most promising aspects of AI.
What is Machine Learning?
Machine learning is the process of a machine (usually a computer or series of computers) accomplishing a task without being specifically instructed on how to complete that task. A normal computer application will follow a series of control structures that tell it how to react in various ways. For instance, I see a red light, then stop, or if a house is 1200 square meters then it would cost $150,000 in a specific market.
What Differentiates Machine Learning From AI?
The difference between ML and AI is that AI does not have a specific set of instructions, but is trained to look at a large set of data and then infer or guess what the outcome for a similar set may be. In our housing pricing example, the system may be given information like this:
| # | Square Footage | Sale Price |
|---|---|---|
| 1 | 1200 | $150,000 |
| 2 | 900 | $120,000 |
| 3 | 1500 | $160,000 |
| 4 | 1000 | $140,000 |
| 5 | 1350 | ? |
The system has the prices of the first four houses, and from that information, AI will try to predict what the estimated price may be based on the prior data set provided.
If we graph these prices, we can see what the data looks like visually, which can help us understand what a Machine Learning system will be doing:
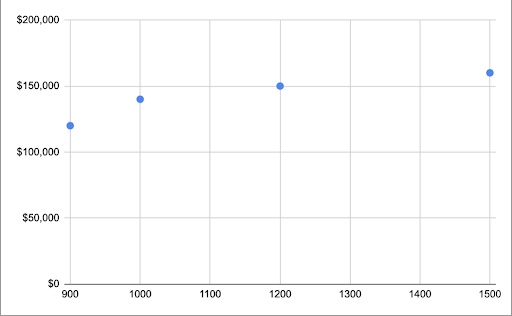
One simple way to make a prediction about what the price of the 1350 square meters house would be to just try to draw a line that intersects as closely as possible the data in our set. The output will look similar to this:
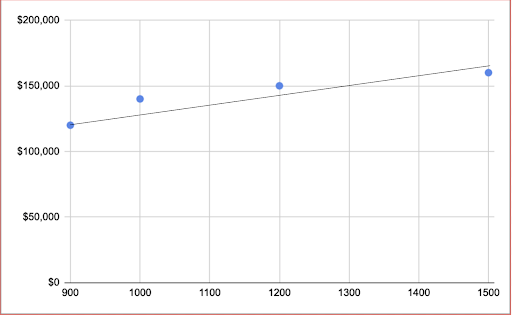
We can see that this is not a perfect fit, and in fact there is no straight line that is a perfect fit but if we do our best to fit the line to the existing data then we can make a pretty good guess, or inference about what the price of the 1350 sq m house will be. It will probably be a bit more than the 1200 sq m house and a bit less than the 1500 sq m house.
The mathematical equations that define a line have two variables in them: the point at which it crosses the vertical axis and the slope of the line. The goal of our Machine Learning algorithm would be to pick those two values to best fit the data. We won’t go into all the math behind this solution but a line can be described as: Y = a + bX
Where a is the intersection with the Y-axis and b describes the slope of the line.
It turns out if you use the quadratic equation, (Y = aX2 + bX +c) it will give us a curve that better fit this data. That curve will look something like this:
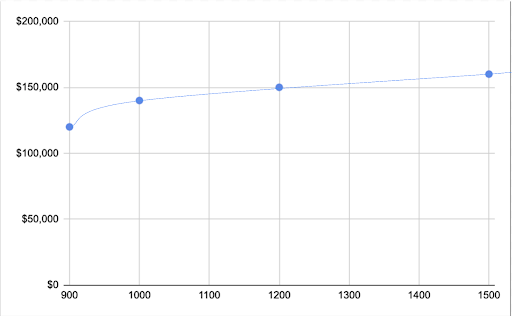
As you can see this fits much better but data like this is not like the real world. The truth is we will do our best to fit the curve to the data we have.
Types of Machine Learning
There are several types of machine learning systems. They are classified by how they use the data to learn and what types of data they work with. The three types of Machine Learning we will cover in this article are Supervised, Unsupervised, and Reinforcement Learning.
Supervised Learning
The housing price example above is a form of supervised learning. With supervised learning, we feed the algorithm a bunch of data of real inputs and real outcomes. In our example, we may have hundreds of houses and their square meterage. This data is called the training data. The algorithm will look to find a curve or line that fits the training data. When it does it can use that curve or line to predict where the price of a different house will fit.
Unsupervised Learning
With supervised learning, you have a “training set” of data with real inputs and real outputs. This allows us to infer, or guess, what the output for a new input will be. For unsupervised learning, we only have input data. This data is not already labeled or classified prior to its input. The goal of unsupervised learning is to group together similar items.
As an example, we will use the dataset based on the 2019-2020 South African Rugby team offensive starters. We will plot their heights and weights and try to categorise them without knowing anything else about them. The dataset is:
| Height (in inches) | Weight (in lbs.) |
|---|---|
| 70 | 185 |
| 79 | 315 |
| 78 | 309 |
| 75 | 300 |
| 77 | 321 |
| 77 | 320 |
| 75 | 260 |
| 73 | 211 |
| 75 | 230 |
| 71 | 224 |
| 70 | 242 |
If we plot this information out on a graph, it looks like this:
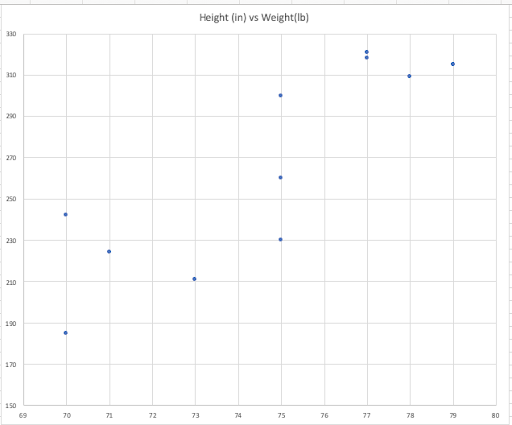
An unsupervised learning algorithm that is appropriately tuned would be able to easily group together four of the players into one group (red circle) and five others into another (green circle), leaving two players that may not be as easy to categorize.
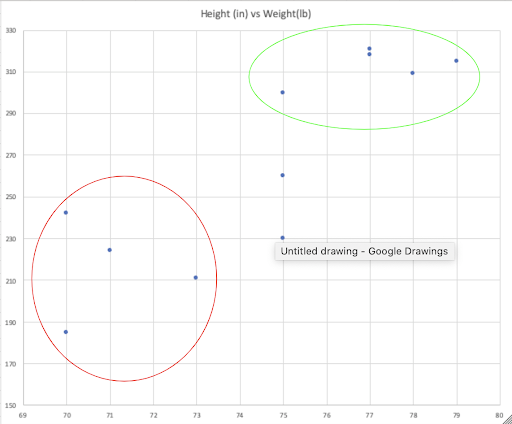
It turns out that the red circles are the Hooker, tighthead and Loosehead prop who tend to be smaller and faster players while the green circle contains the locks and flankers who tend to be bigger and stronger players. The two uncategorised players are the fullbacks and half-backs. An unsupervised learning system will use various statistical models to try and reach a logical grouping of all of the players in the dataset.
Reinforcement Learning
Reinforcement learning is a system that provides both positive and negative feedback to a system based on the choices delivered. An excellent example of this may be a personal recommendation system.
If you have ever watched Netflix or ShowMax, you know that it comes up with suitable recommendations for you based on your viewing history. Netflix uses a reinforcement learning system to determine what you may or may not like. The inputs for this dataset are what shows you have previously watched, and what others who have watched similar shows also liked.
This system then suggests shows it thinks are similar to your tastes. The response (or reinforcement) is whether or not you actually select and watch the suggested show. If you like a particular show and 100 other people that liked that show, also like a similar show, then the system may recommend another show related to your tastes based on all of those choices.
As time goes on, the system learns more about you and your preferences based on whether you choose to take the suggested recommendations or not. It then evolves its algorithm to be more knowledgeable and then makes future recommendations based on those prior selections.
A Practical Example
The Spam Filter
Every day you probably receive a number of spam email messages. In the past, this was a huge problem, but in more recent years, the email providers have begun to use machine learning to solve this real-world problem.

One system that is used takes a series of emails in as training data. Half are known to be spam messages, and half are known not to be spam messages.
The system then keeps track of every word (or even every phrase or series of words) in both data sets. The spam filter can then predict the likelihood that a specific term, phrase, or series of words that are contained within an email are spam or non-spam messages. Using this data, you can determine from the words of a new message the likelihood that if the email is a spam message or not.
Given this dataset:
|
Word |
Spaminess |
|
Beneficiary |
97 |
|
Cash |
82 |
|
is |
50 |
|
aunt |
2 |
|
home |
20 |
If a message containing the words “Beneficiary,” “Cash,” and “is,” we could determine that there was about a 77% chance the message was spam. If, however, the message said, “your aunt will be home at 5 pm,” there would be about an 11% chance that the message is spam. Modern spam filters have far more data and thus have become much more accurate at determining if messages are spam or not.
Conclusion
Machine Learning is a concept that has been around for quite some time. Its applications have recently become more and more useful in our everyday lives. As this technology improves, these systems will be able to do more complex tasks with less human intervention.
